
RAID or ZFS Storage Guide
It’s 2022 and you want to set up some local large disk storage. What should you use?
I recommend using ZFS as a good general-purpose storage solution and I want to cover what it does well and what it doesn’t do great at. I’ve been running a small ZFS pool for a few years now and while I seen some issues, still recommend it as the best path for most users.
ZFS, previously known as the Zettabyte file system from Sun Microsystem’s Solaris operating system, is a RAID-like solution that boosts more flexibility and speed improvements over the more conventional hardware-level RAID. A zettabyte is roughly a trillion terabytes, so they are implying it is “unlimited” storage, but it definitely has a limit that you will probably never run into.
- ZFS combines Volume Management and File System together allowing it to do better optimizations than conventional RAID that doesn’t understand how each filesystem stores and reads data on it.
- Pool Level Snapshots with little performance impact as it freezes cells after a snapshot, forcing any updates to write to new cells leading to near instant snapshots, but potentially slower reads if it has to search through multiple snapshots.
- Native compression and deduplication (detects blocks stored multiple times and stores it only once), just don’t expect to get much especially if you are storing highly compressed content to start with, such as images, music or movies.
- ARC (Adaptive Replacement Cache) allows disk operation to run in memory instead of SSD or HD speed but only if the data is in the cache. This is how large file servers can use slow disks but with a lot of memory can still perform well above expected speeds.
Setup
My experience of setting up traditional RAID is, its an ok process as long as you don’t ever need to touch it.
It starts with restarting the machine multiple times as you attempt to get into the RAID card’s BIOS that appears briefly after your normal BIOS finishes. Many consumer machines have RAID disabled but you can enable it in your BIOS. Once into the RAID setup, it’s normally a terse text-based screen where you can set up a RAID level with the disks it sees. After that point, the operating system will only see the RAID disk and not the physical disks. When all the disks are new, and you don’t have any data, the process isn’t bad. It’s more daunting when you are recovering a damaged disk and hoping you don’t accidentally wipe the entire array when you bring in the new disk.
Then enter ZFS. You don’t have any BIOS setup and the OS will know about the underlying disks.
Some Linux distros don’t have ZFS installed by default, but it’s a simple install with your package management system. If you get an error trying to run zfs then install it with sudo apt install zfsutils-linux
lsblk
# Will list out the disks on the machine and get you their /dev/___ address
ls -lh /dev/disk/by-id/
# mirrors the data between both disks, the size will be whatever the smallest disk is, disk read/write speed will be of the slower drive
sudo zpool create zfs-pool mirror /dev/disk/by-id/ata-ST14000NM0018-2H4101_ABC1234A /dev/disk/by-id/ata-ST14000NM0018-2H4101_ABC9876B
# raidz creates a parity disk and stripes the remaining, handles 1 drive failure, size will be sum of the stripped disks, disk read/write speed will be roughly the speed of the disk multiplied by the array size
# (e.g. 150MB/s * 3 drives = 450MB/s ballpark)
# (e.g. 150MB/s * 5 drives = 750MB/s ballpark)
sudo zpool create new-pool raidz /dev/sdb /dev/sdc /dev/sdd
# raidz1 creates 2 parity disk and stripes the remaining, handles 2 drive failures, size will be the sum of the stripped disks
sudo zpool create new-pool raidz1 /dev/sdb /dev/sdc /dev/sdd
# If you mess up and want to redo it
sudo zpool destroy <poolname>
Day to Day Commands
ZFS does most of its work on its own but sometimes you want to check in on it.
zpool status
pool: ninetb-pool
state: ONLINE
scan: scrub repaired 0B in 0 days 06:27:58 with 0 errors on Sun Nov 14 06:51:59 2021
config:
NAME STATE READ WRITE CKSUM
ninetb-pool ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
ata-ST3000DM008-2DM166_AAAAA ONLINE 0 0 0
ata-ST3000DM008-2DM166_BBBBB ONLINE 0 0 0
ata-ST3000DM008-2DM166_CCCCC ONLINE 0 0 0
errors: No known data errors
zpool import <poolname> zpool export <poolname>
Importing allows you to load the pool on a new machine, and exporting closes up the disks to be ready to move between machines. You don’t have to close the pool to open it, especially if the machine dies and you are trying to get to the data, but if you have a heads up, telling it to close will make the import go smoother.
zpool history
zpool list -v
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
ninetb-pool 8.12T 6.29T 1.83T - - 5% 77% 1.00x DEGRADED -
raidz1 8.12T 6.29T 1.83T - - 5% 77.5% - DEGRADED
ata-ST3000DM008-2DM166_AAAAAAA - - - - - - - - DEGRADED
ata-ST3000DM008-2DM166_BBBBBBBB - - - - - - - - ONLINE
ata-ST3000DM008-2DM166_CCCCCCCC - - - - - - - - ONLINE
Check out more commands at https://www.thegeekdiary.com/solaris-zfs-command-line-reference-cheat-sheet/
Recovering after a disk failure
One day you find that your ZFS array is in a degraded state. One of the drives will be damaged and ZFS will kick into overdrive to keep your files accessible. If you don’t log into the server often, you might not notice it. I actually was running in a degraded state for weeks before I started investigating why my transfer speeds were consistently lower than usual.
zpool offline ninetb-pool ata-ST3000DM008-2DM166_AAAAAAAA
zpool replace ninetb-pool 6038587588943812251 ata-ST3000DM008-2DM166_DDDDDDDD
zpool clear ninetb-pool
zpool scrub ninetb-pool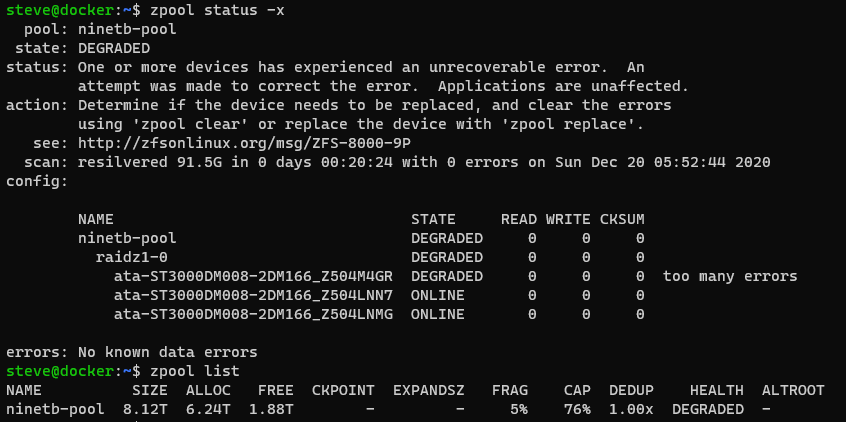
Snapshots
Is a way to save a moment in time for the pool. ZFS will not change any data, and any new writes to the pool will be written to new locations on the disk.
zfs list -t snapshot
zfs snapshot poolname/snap@20210425 zfs send <snapshot> <location>
Deduplication
This feature allows repetitive data and files to be stored only once on the disk but act as though it is stored multiple times in various directories.
Be warned it uses a lot of memory and every write has to check to see if that block already exists. The rough calculation is about 5GB for every TB of storage. This will use up memory that would have been used for ARC cache.
5GB * x TB = in-memory DDT requirements
5GB * 5TB = 25GB of memory
sudo zfs get dedup sudo zfs set dedup=on <poolname> sudo zfs set dedup=off <poolname>
In the end, I do not recommend turning this on. The performance impact is heavy if you have large video files and you won’t get much benefit at the end of the day.
To see how much memory is used for Dedup if you have it enabled.
zpool status -D
dedup: DDT entries 39023888, size 451B on disk, 145B in core
Multiply the entries (39023888) by the core size (145B) to get (5.6GB memory usage)
Compression
ZFS has a transparent compression option which is great for the storage of uncompressed data like log or text files. You get the storage benefit of compression but is completely transparent. You won’t have to uncompress zip files.
sudo zfs set compression=on <poolname> sudo zfs set compression=off <poolname> sudo zfs get compressratio
You have compression enabled when the files are being written to. If you turn it on or off later, the existing files do not change their state. You will have to copy them off and back on to align them.
In the end, I also do not recommend turning this on for pools that have large compressed objects like videos or zips. You will still pay a compression penalty and not get any benefit. If you want to use this, divide up the pool so your large already compressed files are being stored without zfs compression.
Encryption
To encrypt the drives, you have to do this during pool creation
sudo zpool create <poolname> mirror /dev/disk/by-id/ata-ST14000NM0018-2H4101_AAAAA /dev/disk/by-id/ata-ST14000NM0018-2H4101_BBBBBBB -O encryption=aes-256-gcm -O keylocation=prompt -O keyformat=passphrase
Using a prompt method is nice if you want to make the disk only readable when a user can enter a password, but not if you want it to be transparent. There are other options including one where it uses a pktool key file that is stored locally or on a web server. Unfortunately the documentation to do this is quite difficult.
Upsides
Transferable between Linux machines. Unlike so many other RAID solutions, if this machine fails, you basically need to buy a replacement to salvage your data. This doesn’t lock you into anything, you probably have another Linux machine that you can import the pools and get to your data.
No more RAID controllers. You can access and check in on your ZFS pools from the command line whenever you want. No more rebooting to get into RAID setup.
Downsides
With all of the good things, let’s take a look at what isn’t great on ZFS.
Upgrading when you run out of space is still a huge pain. It’s often easiest to just get all new disks and create a new pool, transfer the data to it, and remove the old pool. When I first got started with ZFS, I used to work with a Drobo storage unit that could easier just handle removing any of the disks and replacing it with a larger one. It would then reshuffle the data and you were all set. I thought ZFS would be able to do that and it definitely cannot. Another way to add storage is to just add another 2 drives in mirror and create a new pool that runs alongside the existing pool. If you plan to add storage later on, I would highly recommend not running everything in one large pool or it will make it difficult to expand.
Native Compression in ZFS is probably not worth it, most files today are already using something like gzip so compressing these files a second time doesn’t give you much of a space improvement but you still get the CPU overhead. It feels mostly transparent, but if you watch top on the server, you will see the cpu spiking during file reads.
Native Deduplication in ZFS uses too much memory and cpu for most users. If you enable them, every read/write has to do lookups in the dedup table to find the real data and you are losing alot of memory that would of been used as cache to hold the dedup table in memory.
Native Encryption in ZFS is difficult to enable.
Scrubbing/Resilivering is a performance hit. The default behavior is the ZFS subsystem will just randomly scrub the disks when needed. This untimed job will severely impact your read/write until it finishes. I would highly recommend setting up a CRON job to run zpool scrub <pool-name> so it is at least predictable when it will be slow.
Command-line syntax between zfs vs zpool is a little annoying. This isn’t a huge deal, but knowing which subcommand is in which command is hard to remember when you don’t use it very much.
If you want to use ZFS on a mac, I would recommend against it. ZFS does work on mac, you have to install openZFS and it can load a ZFS array that was created on linux. My issue is more that mac is not a great OS for this. After a power cycle, it can’t mount the disk until it has been logged in.

FlashPrint Opens Off-Screen
Reducing WordPress Load from XMLRPC

I'm a 36 year old UIUC Computer Engineer building easy to use tech to simplify our complicated lives with an interest in golang, rust, 3D printing, ESP32 and Arduinos.
cool explained very well.